이 글은 원문에서 참고했고 약간의 내 생각을 의역으로 덧붙인 글입니다.
This artice is come from this Site
Scaling to 100k Users
많은 스타트업들이 그러하듯 매일 수많은 사용자들이 계좌를 등록하고 엔지니어링팀은 이 서버가 돌아가게 만들게 하기 위해서 불철주야 노력한다.
많은 사용자들이 들어오는 것은 좋지만, 제로에서부터 수십만에 이르는 사용자들을 대상으로 해서 Web app을 설계하고, 유지하는 것에 대한 방법은 정보가 매우 부족하다. 보통 이런 류의 정보는 서버가 폭발하거나 접속자수가 너무 많아 병목현상을 일으키게 되면 필요하게 된다. (종종 두번 정도 발생한다)
그런데 내가 확장성이 높은 사이드 프로젝트를 하면서 발견한 것은 이러한 과정 중 대부분은 정형화된 패턴을 가지고 있다는 것이다.
그래서 나는 이런 정형화된 패턴을 글로 옮겨보려고 한다. 사진 공유사이트인 Graminsta라는 사이트를 예시로 1에서 10만명까지 사용자가 늘어나게 될 때 어떻게 바뀌게 되는지 알아보자.
1 User: 1 Machine
웹사이트든, 모바일 앱이든, 거의 모든 애플리케이션에는 세 가지의 핵심 구성요소가(삼신기)가 있다.
바로 API, DataBase 그리고 Client(보통은 앱 또는 웹사이트)
DB는 영구데이터를 저장하고 API는 해당 데이터에 대한 요청과 그와 관련된 요청을 처리한다. Client는 그 데이터를 user에게 전달하게 된다.
나는 현대 어플리케이션 개발에서는 클라이언트를 API와 완전히 독립적으로 만든다는 것을 알아냈는데, 이렇게 만들게 되면 앞으로 확장성을 생각하기가 더 쉽기 때문일 것이다.
처음 어플리케이션을 개발할때에는 이 세 가지를 모두 한 서버에 돌리는 것은 괜찮다. 어떻게 보면, 우리의 개발환경과 비슷하다. 한 엔지니어가 API, Client, DB를 모두 한 컴퓨터에서 실행하는 것처럼 말이다.
그러니까 이론적으로는 DigitalOcean Droplet이나 EC2 서버 한 개에다가 배포가 가능하다. 아래처럼

그렇기는 하지만, 만약 Graminsta 프로젝트가 한 사람 이상의 유저가 사용하기를 원한다면 Database 계층을 나누는 것이 보통은 맞다.
Amazon RDS를 사용해서 나누거나 Digital Ocean에서 제공하는 Managed Database와 같은 관리형 서비스로 분할하는 것은 꽤 도움이 된다.
10 Users: DB 계층 나누기
단일 컴퓨터 또는 EC2 인스턴스에서 자체 호스팅하는 것보다 약간 더 비싸긴 하다. 하지만 이러한 서비스를 이용하면 Multi-region Reduncy, Read replica, 자동 백업 등 편리한 추가 기능을 쉽게 얻을 수 있다.
지금까지의 Graminsta 시스템의 모습이다.
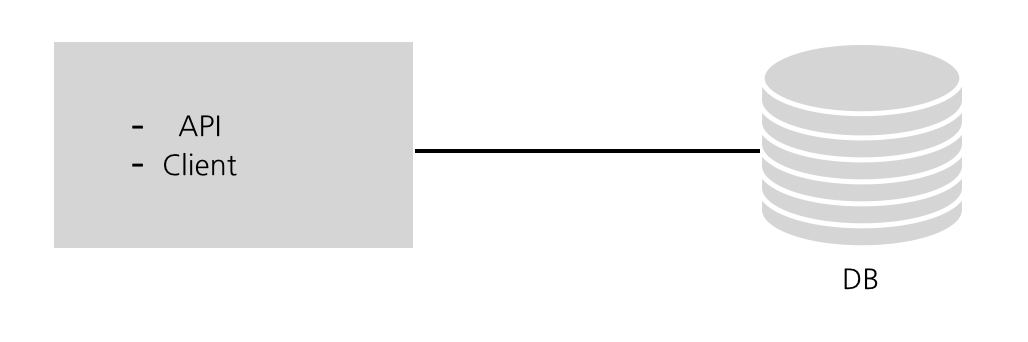
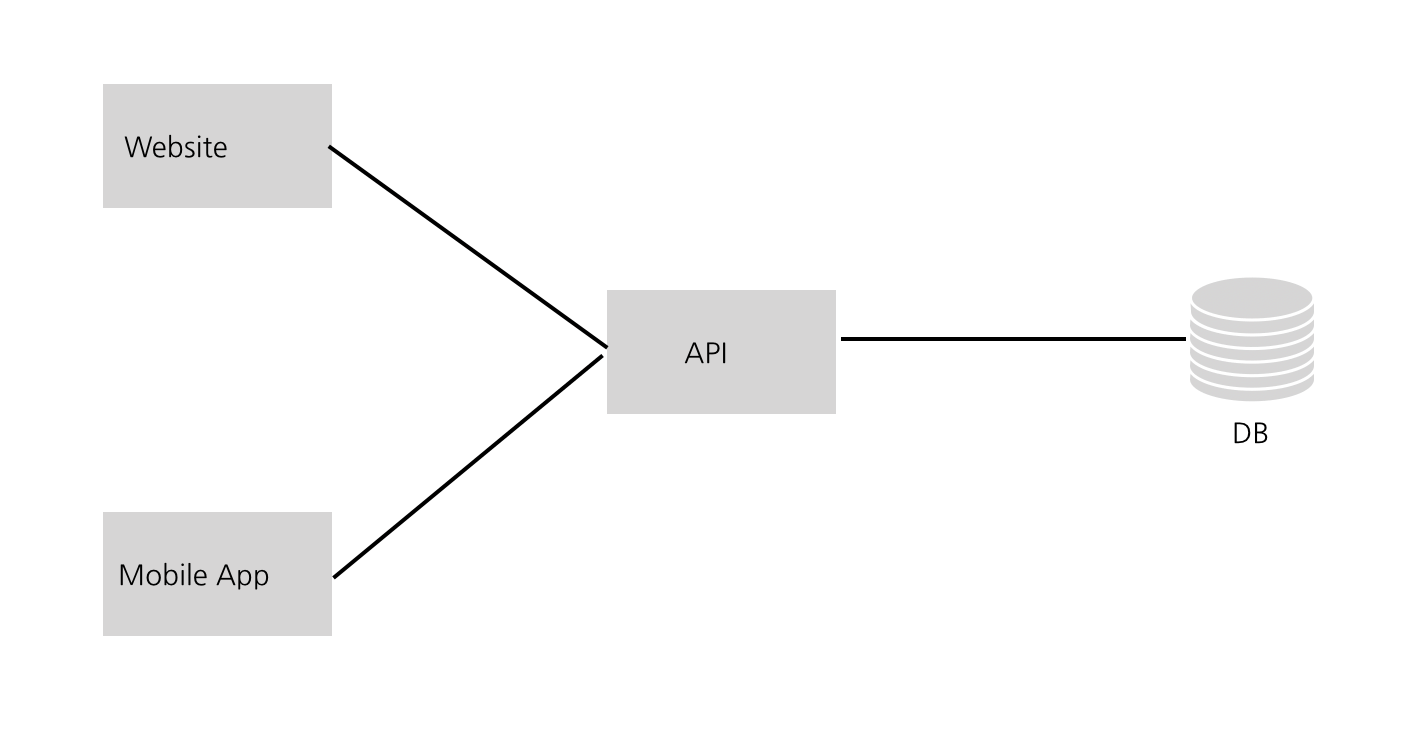
100 Users : Client 나누기
운좋게도, 초기 유저들이 Graminsta를 꽤 좋아한다. 이제 점점 트래픽이 안정적으로 유지되기 시작하니 Client를 나누어야 할 때가 되었다. 한 가지 명심해야 하는 것은 Client를 잘 나누는 것이 확장가능한 어플리케이션을 구축하는데 있어서 중요한 요소라는 것이다.시스템의 어떤 한 부분이 더 많은 트래픽을 얻으면 자체 트래픽 패턴을 기반으로 서비스를 확장할 수 있도록 분할 할 수가 있다.
이래서 나는 Client를 API와 별개로 만드는 것을 좋아한다. 이 방식은 웹, 모바일 웹, iOS, Android, 데스크톱 앱, 타사 서비스 등 여러 플랫폼에 대한 구축을 쉽게 만들 수 있게 한다. 모두 같은 API를 사용하는 Client일 뿐이다.
같은 맥락에서 사용자들에게 얻는 가장 큰 피드백은 Graminsta를 스마트폰에 설치하기를 원한다는 것이다. 그래서 우리는 모바일 앱을 출시하기로 한다.
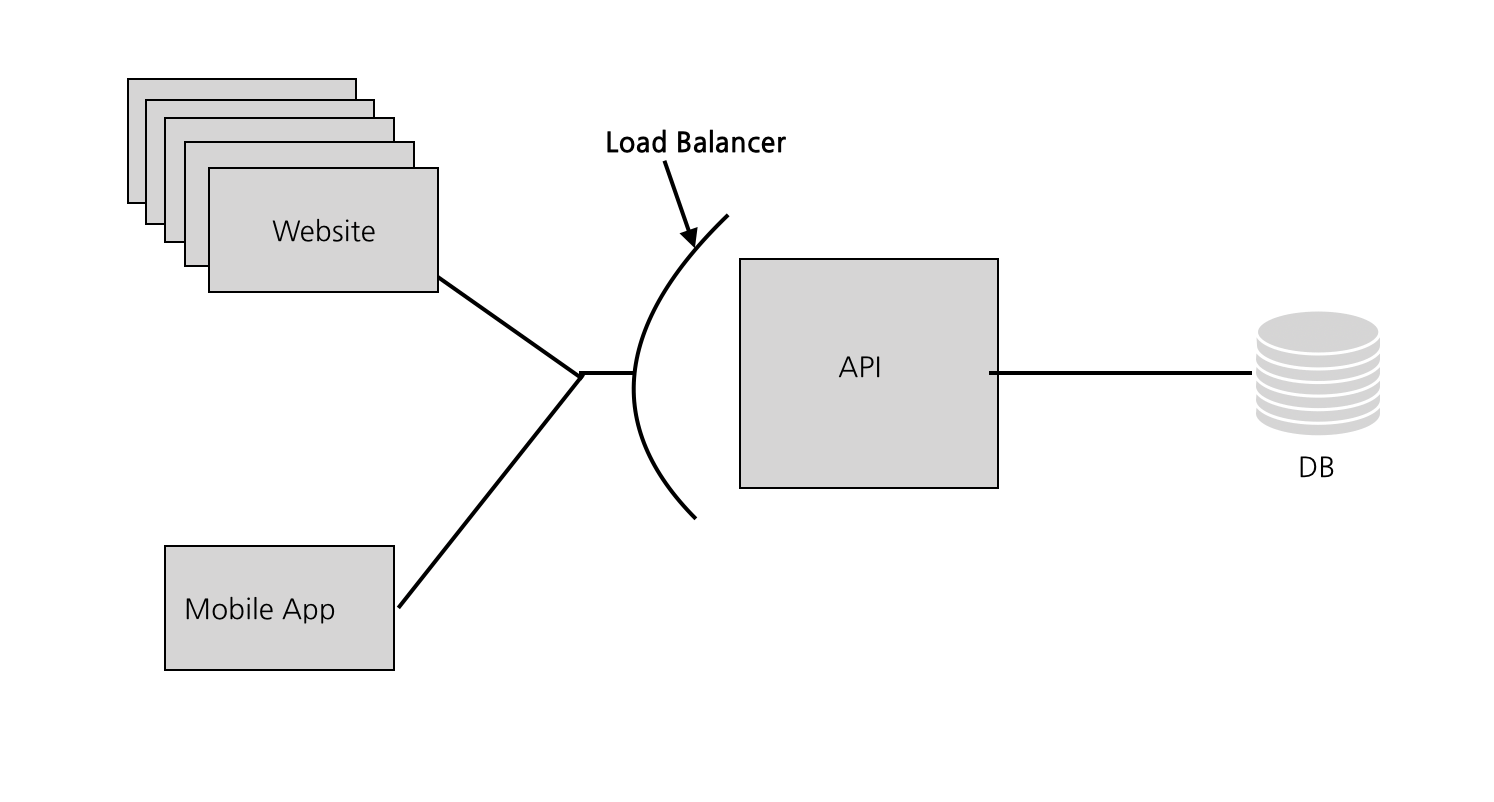
1,000 Users: 로드밸런서 추가
Graminsta가 입소문을 타기 시작한다. User들이 사진을 여기저기서 올리기 시작한다. 점점 더 많은 가입자가 생긴다. 우리가 만든 하나밖에 없는 API는 몰려드는 트래픽을 처리하느라 어려움을 겪기 시작한다. 더 많은 컴퓨팅 파워가 필요한 시점이다.
로드밸런서는 매우 강력크 하다. API앞에 로드밸런서를 배치하게 되면 트래픽을 서비스의 인스턴스로 라우팅해 보내준다. 이를 통해 수평적 확장(동일 코드를 실행하는 서버 하나를 더 추가하여 처리할 수 있는 request량을 증가 시키는 것)이 가능해진다.
웹클라이언트와 API앞에 로드밸런서를 배치한다. 즉 API와 웹클라이언트 코드를 실행하는 여러개의 인스턴스가 있을 수 있다. 로드밸런서는 트래픽이 가장 적은 인스턴스로 request를 라우팅한다.
이렇게 하게 되면 우리는 Redundancy도 가져갈 수 있다.
Redundancy 그러니까 한 개 장비가 뻑이 나더라도 다른 장비가 있으므로 안정적으로 운영을 가져갈 수 있음
한 인스턴스가 다운되더라도(과부하되거나 충돌이 일어나도) 전체 시스템이 다운되는 대신 다른 인스턴스가 requset를 받아서 처리할 수 있다.
그리고 또 로드밸런서는 오토스케일링도 가능하다. 로드밸런서를 설정하게 되면 트래픽이 많이 몰리는 시간(뭐 예를 들면 추석 KTX예매)에는 인스턴스를 늘리고, 잠잘 시간에는 인스턴스를 줄일 수 있다는 뜻이다. 로드밸런서를 추가하면 우리의 API 계층은 어떻게 보면 무한대로 확장이 가능하다. 더 많은 Requset가 오면 계속해서 인스턴스를 늘리면 된다.
이 시점에서 보면 Heroku나 AWS의 Elastic Beanstalk 같은 PaaS 회사들이 즉시 제공하는 것과 매우 유사하다.(이래서 인기가 높음), Heroku는 Database를 별도의 호스트에 두고 자동 확장으로 로드 밸런서를 관리한다. 또 웹 클라이언트를 API와 별도로 호스트할 수 있도록 한다. 이래서 프로젝트나 초기 단계의 창업에 헤로쿠와 같은 서비스를 이용해야 하는 큰 이유인데, 초기 단계에 필요한 것들이 기본으로 제공되기 때문이다.
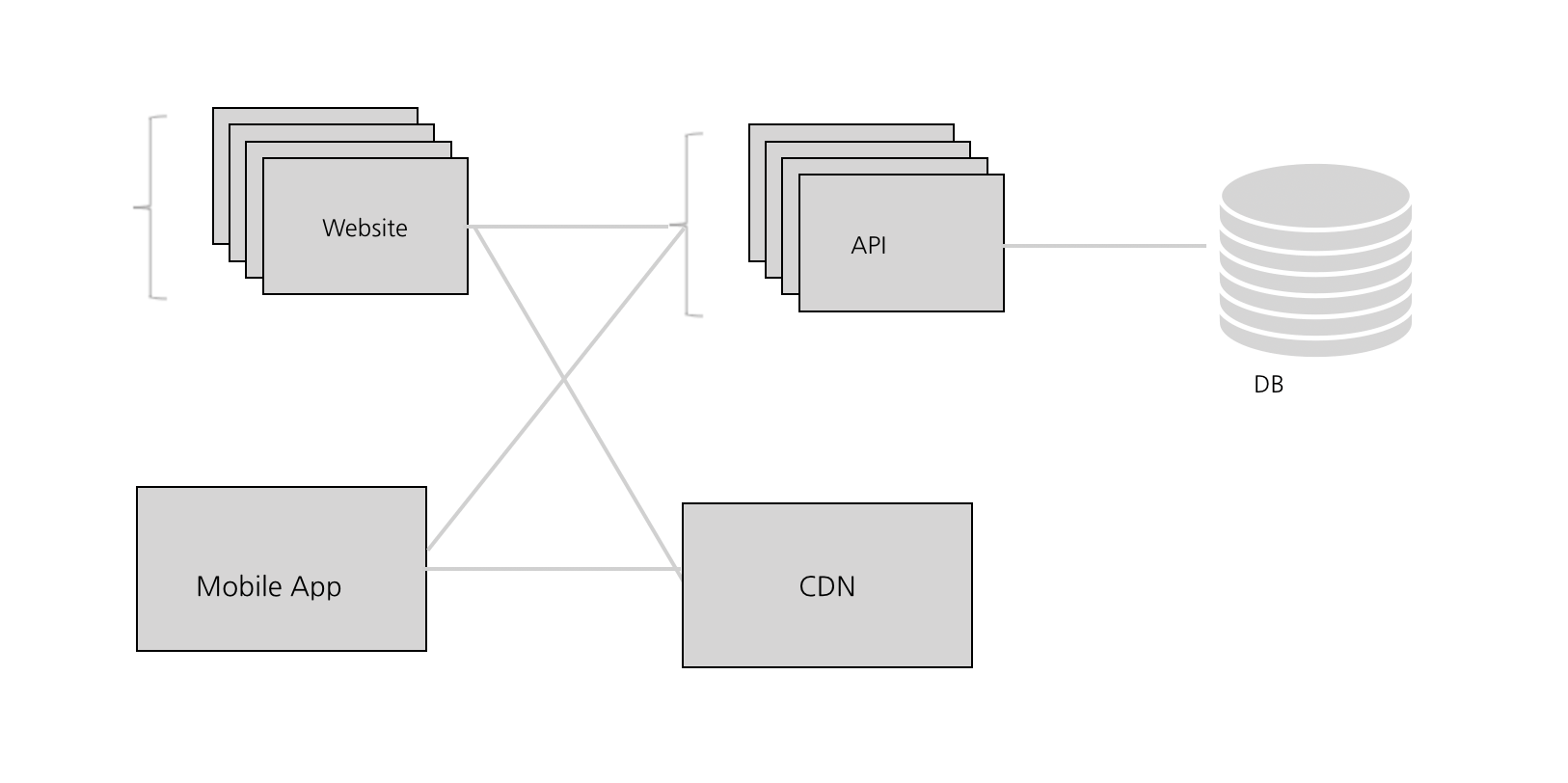
10,000 Users: CDN
처음부터이 작업을 수행했어야 하지만, Graminsta가 워낙 빠르게 변하고 있어서 하지 못했다. 만명이나 되는 유저들이 이미지를 제공하고 업로드하면 서버에 너무 많은 부하가 걸리기 시작한다.
이 시점에서 static 콘텐츠(AWS의 S3 또는 Digital Ocean’s Spaces)를 호스팅하기 위해 클라우드 스토리지 서비스를 사용해야 한다. 일반적으로, API는 이미지나 이미지 업로드를 제공하는 것과 같은 것들을 다루는 것을 하면 좋지 않다.
클라우드 스토리지 서비스에서 사용할 수 있는 것 중 하나는 것은 바로 그 유명한 CDN이다. CDN은 전 세계의 각기 다른 데이터 센터에서 유저가 올린 이미지를 자동으로 캐싱할 것이다.
즉 우리의 메인 데이터 센터는 서울에서 서버 호스팅을 돌리고 있지만, 만약 누군가 캘리포니아에서 이미지를 요청한다면, 클라우드 공급자는 자주 쓰이는 데이터의 복사본을 만들어서 캘리포니아의 데이터 센터에 저장한다. 그렇게 되면 다음에 같은 자료를 요청한 사람은 훨씬 더 빨리 데이터를 받을 수 있다. 이 서비스는 로딩하는 데 오랜 시간이 걸리는 이미지나 비디오와 같은 것들을 공유할 때 효과적이다.
100,000 Users: 데이터 계층 확장하기
CDN이 많은 도움을 주었다. Graminsta는 점점 더 인기가 많아지는 중이다. 유명 유튜브 계정인 와썹맨과 워크맨이 계정을 만들었고 많은 사진과 이야기들을 올리고 있다. 다행히도 로드밸런서가 잘 동작하는지 API CPU의 메모리 사용량은 전반적으로 낮게 유지되고 있는 중이다. 그런데 이상하게 자꾸 Request를 보내면 응답이 늦게 돌아오거나 시간초과가 발생한다. 왜 그럴까? 왜 이렇게 느리지?
삽질해서 알아본 결과 Database CPU의 메모리 사용량이 80~90%를 육박하고 있다. 최대 한도를 초과하고 있다.
데이터 계층의 확장은 아마도 가장 까다로운고 어려운 부분이다. Stateless한 요청을 처리하는 API 서버의 경우 인스턴스를 더 추가 할 수 있지만 대부분의 데이터베이스 시스템은 이와 같지 않다. 이 경우 널리 사용되는 관계형 데이터베이스 시스템을 알아보게 된다.(PostgreSQL, MySQL 같은 것들).
Caching 캐싱
이런 데이터베이스를 유지할 때 쉽고 좋은 방법이 있다. 바로 캐시를 사용하는 것이다. 캐시를 구현하는 가장 일반적인 방법은 뭐 Redis나 Memcached 같이 메모리 내에 있는 Key value 저장소를 사용하면 된다. 대부분의 클라우드에는 AWS Elasticache나 구글 클라우드의 Memorystore와 같은 관리 서비스 버전이 있다.
캐시는 동일한 정보를 반복적으로 요청할 때 매우 유용하다. 기본적으로 한번만 Database에 요청해서 값을 받아오게 되면 그 다음부터는 다시 Database에 요청할 일이 없다. (내가 캐시를 지우지 않는 이상)
예를 들어 와썹맨의 Graminsta 계정이 인기가 있어서 와썹맨 계정으로 유저들이 갈 때마다 API가 Database에서 와썹맨 계정의 정보를 요청하게 된다. 하지만 이 와썹맨 채널의 계정정보는 바뀌는 일은 사실상 거의 없기 때문에 이런 정보는 캐싱하는 것이 좋다.
Redis의 데이터베이스 결과를 user:id의 만료시간을 30초로 해놓고 값을 캐싱해 놓는다. 그래서 누군가 와썹맨의 채널을 찾아갔을때 Redis에 캐싱된 값이 이미 있다고 한다면 그 값을 주면 된다. 이렇게 하면 와썹맨 채널이 가장 인기있는 것이라고 하더라도 데이터베이스에 영향을 거의 주지 않는다.
또 캐시 서비스에서 얻을 수 있는 이점은 데이터베이스를 확장하는 것보다 더 쉽게 확장이 가능한다는 것이다. Redis에는로드 밸런서와 유사한 방식으로 Redis 클러스터 모드가 내장되어 있다. 그래서 Redis 캐시를 여러 머신에 배포 할 수 있다.
요즘 대부분의 어플리케이션들은 캐싱을 잘 활용한다. 이 방법은 빠른 API를 만들기 위한 필수불가결한 부분이다. 뭐 더 나은 쿼리를 던진다거나 코드를 잘 짜는 것도 일부 방법일 수는 있겠지만, 캐시가 없다면 수백만명에 이르는 사용자로 확장하기에는 충분하지는 않다.
Read Replicas (읽기 복제본)
Database가 꽤나 허덕이고 있기 때문에 이제 우리가 할 수 있는 것은 Database Management System을 사용해서 Read Replica를 추가하는 것이다. 한번 클릭하는 것만으로도 만들 수 있고 이 읽기 복제본은 마스터 DB에 최신상태로 유지된다. 그리고 SELECT를 사용해서 접근 가능하다.
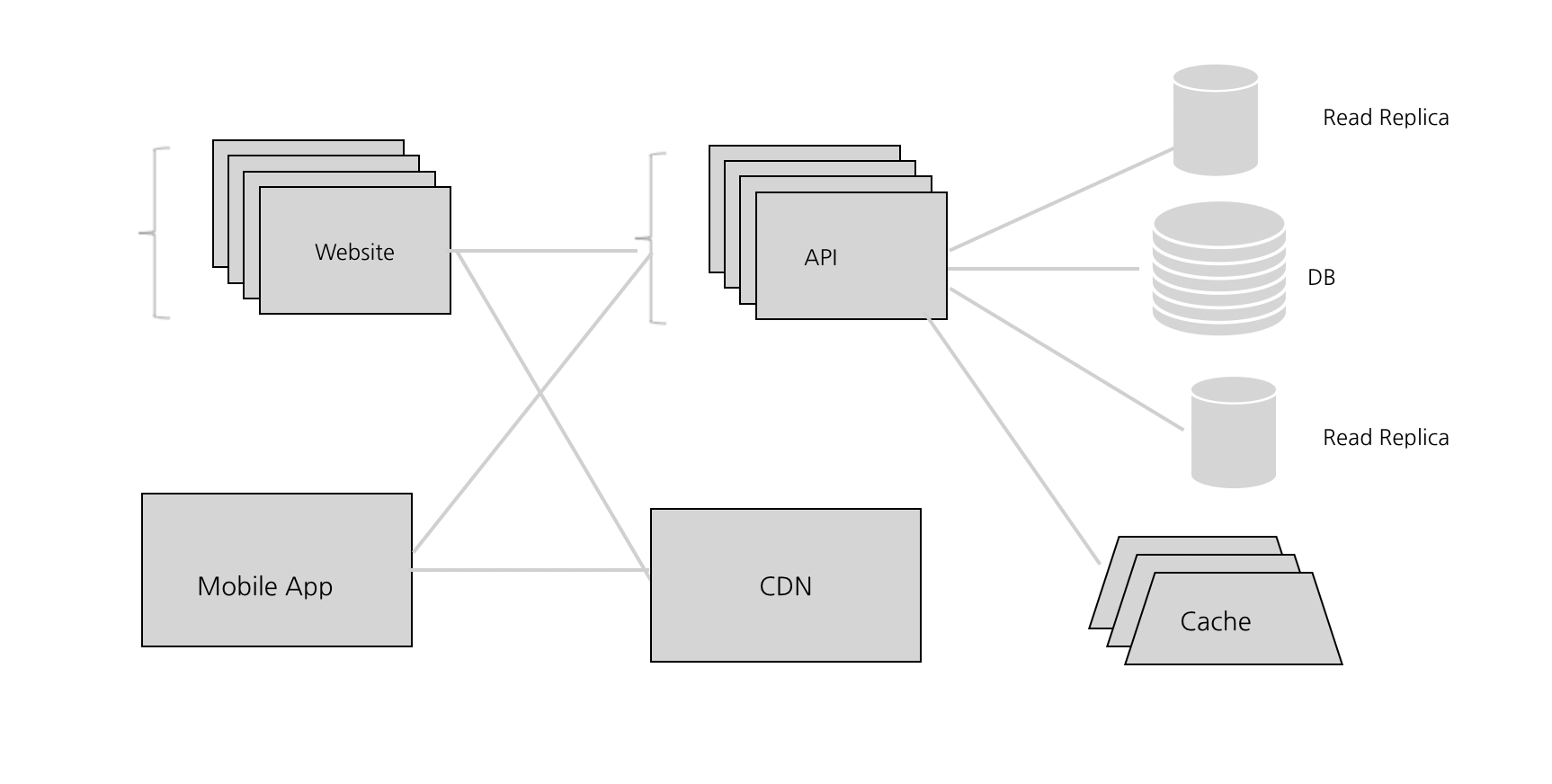
이후
앱이 계속해서 확장함에 따라 우리는 독립적으로 확장할 수 있는 것은 분할해서 서비스하려고 한다. 예를 들어서 우리가 웹소켓을 사용하기 시작한다면 이 웹소켓 처리 코드를 밖으로 빼내는 것이 더 좋다. HTTP Request를 얼마나 보냈느냐에 관계없이 얼마나 많은 웹소켓이 열고 닫앗나에 따라 로드밸런서를 Scale up / Down 할 수 있다.
또한 데이터베이스 계층의 한계에 계속 부딪히게 될 건데 이 때는 데이터베이스를 분할하고 샤딩해야 할 때이다. 두 개다 많은 오버헤드가 필요하지만 데이터 계층을 무한대로 확장할 수 있다는 장점이 있다.
New Relic 또는 Datadog과 같은 서비스를 사용하여 모니터링을 하려고 한다. 이를 통해 어디서 요청이 느리고 개선이 필요한 부분이 어디인지 확인 할 수 있다. 규모를 확장 할 때 종종 이전 섹션의 일부 아이디어를 활용하여 병목 현상을 찾아 수정하는 데 집중하려고 한다.
참고
이 게시물은 내가 좋아하는 High Scalabilty에서 아이디어를 얻어서 썼다. 초반부에 있는 내용을 좀 더 빼서 clould agnostic하게 만들고 싶었다. 좀 더 보고 싶은 내용이 있다면 위 사이트를 참고해서 확인하면 좋을 듯하다.